
bytemd插件开发--将链接渲染为卡片模式
导读
**笔者经常使用语雀这一强大的在线文档编辑网站,在编辑时选择将超链接渲染为卡片的样式。 **
原本的链接样式:

渲染为卡片后的样式:
 可以看到,卡片样式中显示了链接网址的logo、网页标题和网站描述等信息,回想一下网页开发中,是不是就是我们head标签中的有关信息呢?如图所示:
可以看到,卡片样式中显示了链接网址的logo、网页标题和网站描述等信息,回想一下网页开发中,是不是就是我们head标签中的有关信息呢?如图所示:
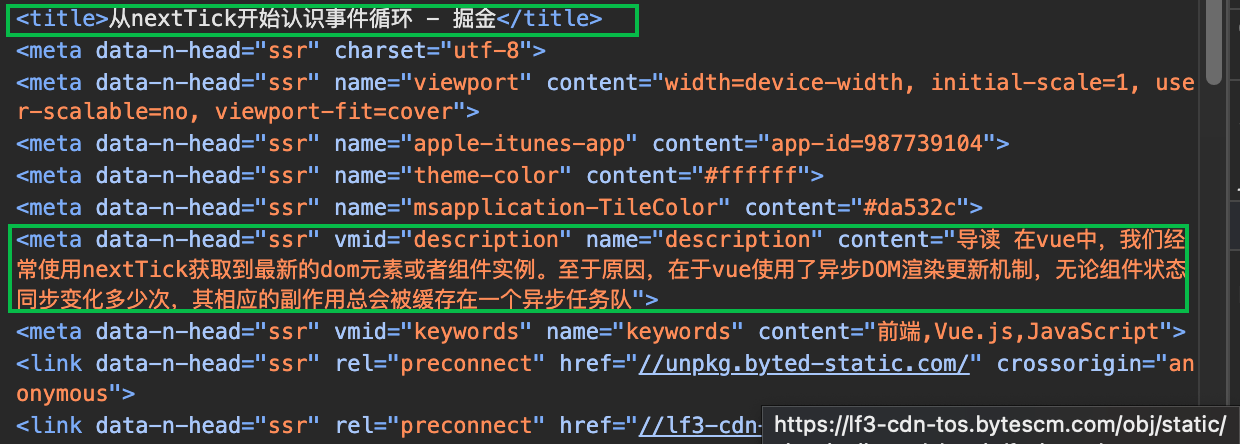
为此,我们需要做的就是要请求目标网页的index.html,然后拿到这些关键信息了,再渲染为卡片的样式。
骨架屏卡片
导读说已经谈到要渲染卡片链接,需要获取到链接网站的一些信息,这肯定要发起一个请求,而请求必定存在耗时,在我们获得链接网址的信息前,卡片链接是无法渲染的;而当网址的信息请求响应之后,又将立刻渲染为卡片,这务必会造成阅读者非常强烈的视觉冲击,显得尤其突兀。为此,我们需要一开始就将链接渲染为骨架屏的卡片样式,以占位符的形式从视觉上告诉用户正在加载,让用户对相关的请求数据有所期待,增强交互体验。

骨架屏其实很简单,只是在将来要显示有关内容的区域加上一个“扫光”的动画效果,数据渲染后移除这个动画就完成了。而扫光的效果其实就是一个背景而已,由于其不是主要内容,这里只贴出相关的样式代码,具体解释分析可以观看bilibili上的视频。
1 | { |
使用puppeteer获取目标网站信息
完成了骨架屏之后,我们就可以去请求获取网页的有关信息了。首先,我们很容易想到使用fetch直接请求目标网站,你会立马发现,由于同源策略的原因直接报跨域的错误。

为此,我们需要通过后端访问目标网站,提取出需要的关键信息后返回前端,而这就要使用到大名鼎鼎的puppeteer了。其可以在后端环境中以chrome浏览器的形式加载网页信息,几乎拥有我们能在chromme浏览器中所有操作的能力。
以下是通过express搭配puppeteer的一个示例:
1 | const express = require('express'); |
在该示例中,将获取目标链接网址的标题、描述、icon和主机等信息。特别需要说明的是,获取icon信息时我们可能拿到完整的链接,也有可能拿到相对路径的资源,这时就需要进一步处理,得到真正能访问的icon链接。
把这些信息返回给前端,就可以真正实现卡片链接了。
默认值和请求超时的处理
从puppeteer拿到网站的主要信息后,将icon,描述信息、网站标题回填到骨架屏时就预留占位dom位置,再去除骨架屏效果,似乎就完成了我们的卡片链接需求。然而,我们必须考虑两个问题:一是我们毕竟是通过puppeteer访问的目标网址,当国内访问外网或者其他一些网站时,存在响应慢甚至无法访问的情况,也就是我们的接口请求可能超时也可能失败;二是网站本身不一定就一定存在<meta name="description" content=""></meta>等标签,会造成我们获取不到我们想要的描述信息和icon链接等。解决这两个问题我们可以增加两处处理逻辑:一是由于网站获取不到对应的元素或者请求失败时我们可以指定默认的值,例如icon链接获取不到时,我们可以使用默认的链接替代,标题使用 **[无标题] **替代,就像语雀的:

**对于请求超时的情况,我们可以同样直接使用默认值进行渲染,直接忽略未完成的请求响应信息,比如设置25s的请求超时,超过了直接渲染,哪怕后续30s+时请求响应了,我们也直接忽略响应结果,当然也可以不忽略,使用响应结果实现二次渲染。当然,**本文还是选择渲染超时忽略响应的方案。
于是,我们可以得到下述的伪代码:
1 | //假定fetchInfo就是我们的请求 |
代码中,fetchInfo是我们的请求,而renderCard是渲染逻辑,通过把逻辑封装在promise,这个promise一定是fulfilled,保证了renderCard始终会被触发且拿到要渲染的数据。
最终渲染结果如图所示:

bytemd插件的开发
明确了基本实现原理,我们接着来实现这个插件。
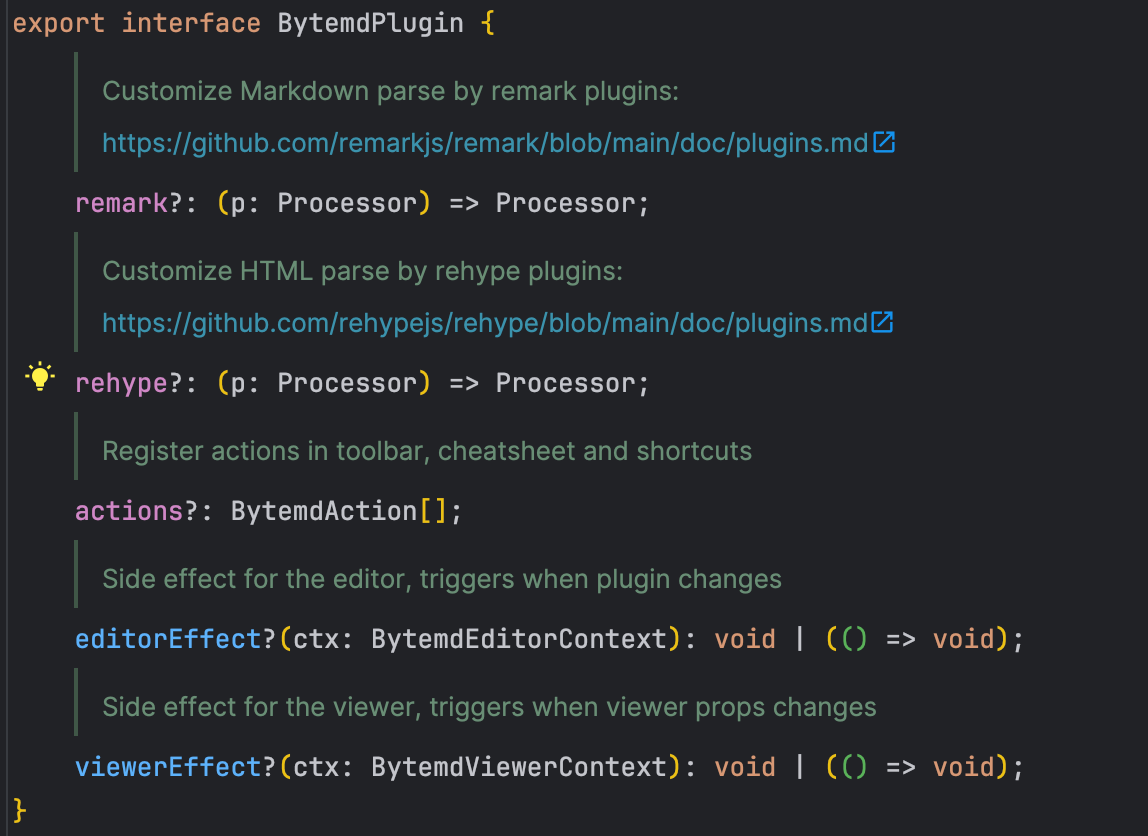
看一下官方插件的返回类型,从上到下依次是:
- remarkjs配置,用于将markdown转换为AST,并转换处理
- rehypejs配置,用于将HTML转为AST,并转换处理
- actions,处于注册编辑器中的工具栏
- editorEffect,编辑器的副作用函数
- viewerEffect,预览区的副作用函数
这里我们仅需使用到remark和viewerEffect两个配置项。首先,我们先看看viewerEffect中接受的参数ctx,也就是上下文的类型
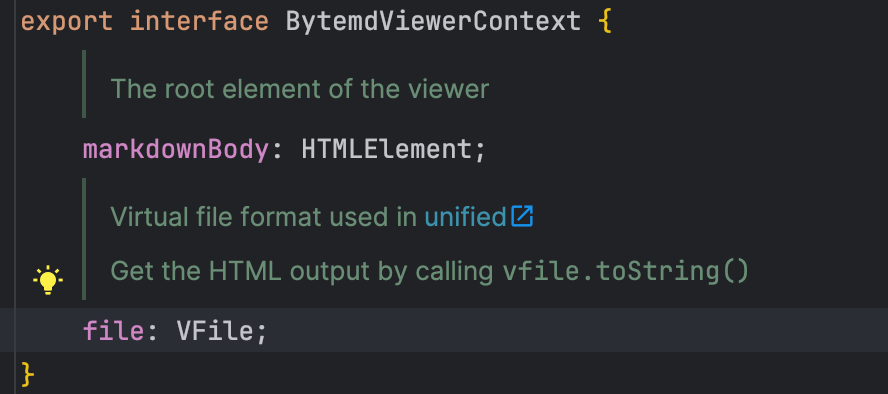
可以看到其中有一个markdownBody,其为渲染为html后的根节点,而我们就是要替换其中跟链接相关的子节点,也就是替换链接相关的html片段。我们知道,markdown中的链接[百度](https://www.baidu.com)会被渲染为<a href="https://www.baidu.com">百度</>,而我们需要将其替换为卡片的HTML,似乎可以直接有:
1 | function cardLink(options:PluginOptions):BytemdPlugin{ |
但是有没有想过:如果a标签不是由markdown的链接语法[]()渲染而来,不就是把不该转换的a标签错误转换了吗?因此,我们需要知道哪些a标签是由markdown中的链接语法转换来的,因此我们需要使用remark配置来识别出markdown的链接节点,并打上tag,最好的方法就是给每一个节点加上一个类名,后续我们可以通过getElementsByClassName()这个DOM API 获取到真正需要处理的DOM节点。
例如:
1 | const eles=markdownBody.getElementsByClassName('card-link-temp') |
markdown节点转换
remark配置里的参数Processor,是由unified这个库提供的,其可以将提供的一些文本内容处理成抽象语法树,也就是转为AST,然后交给各式各样的插件处理。而Processor提供的use方法,就是我们注册插件的入口。插件是一个函数,其会返回一个实际被调用的函数:
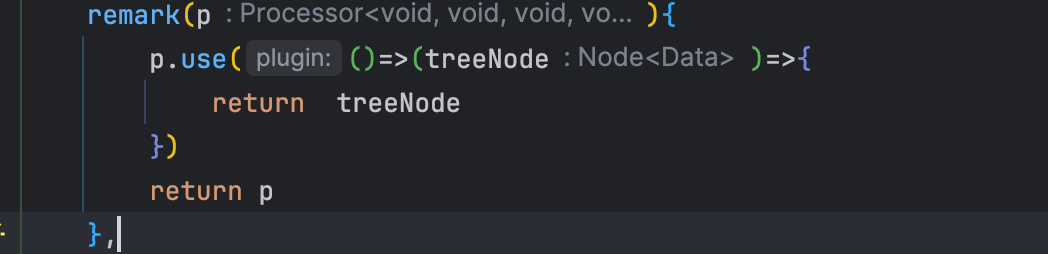
而treeNode就是AST的根节点,我们可以打印看看结构:

从每个节点的type的类型,我们可以明前看到 paragraph就是markdown里的段落、code是代码块、heading是标题等等,接着我们要遍历这个treeNode节点,给其加上特定的渲染类名。而遍历的话我们又可以使用unist-util-visit这个库,这样就不用我们字节写递归了。
1 | import { visit } from "unist-util-visit"; |
导出visit方法,其第一个参数接受根节点,第二个参数既可以指定我们只过滤type为“link”的节点,第三个参数是回调函数,分别接收节点,下标和父节点。通过观察node节点的结构,type为“link”时,其url属性就是链接:

先上我们的处理代码:
1 | visit(tree, "link", (node, index, parent) => { |
这段代码的意思就是指定后续的渲染直接将该节点渲染为a标签,并加上自定义的类名:

html替换
打上了tag,接着我们可以继续在viewerEffect中处理我们的逻辑。
使用getElementsByClassName()获取到所有的需要处理的a标签:
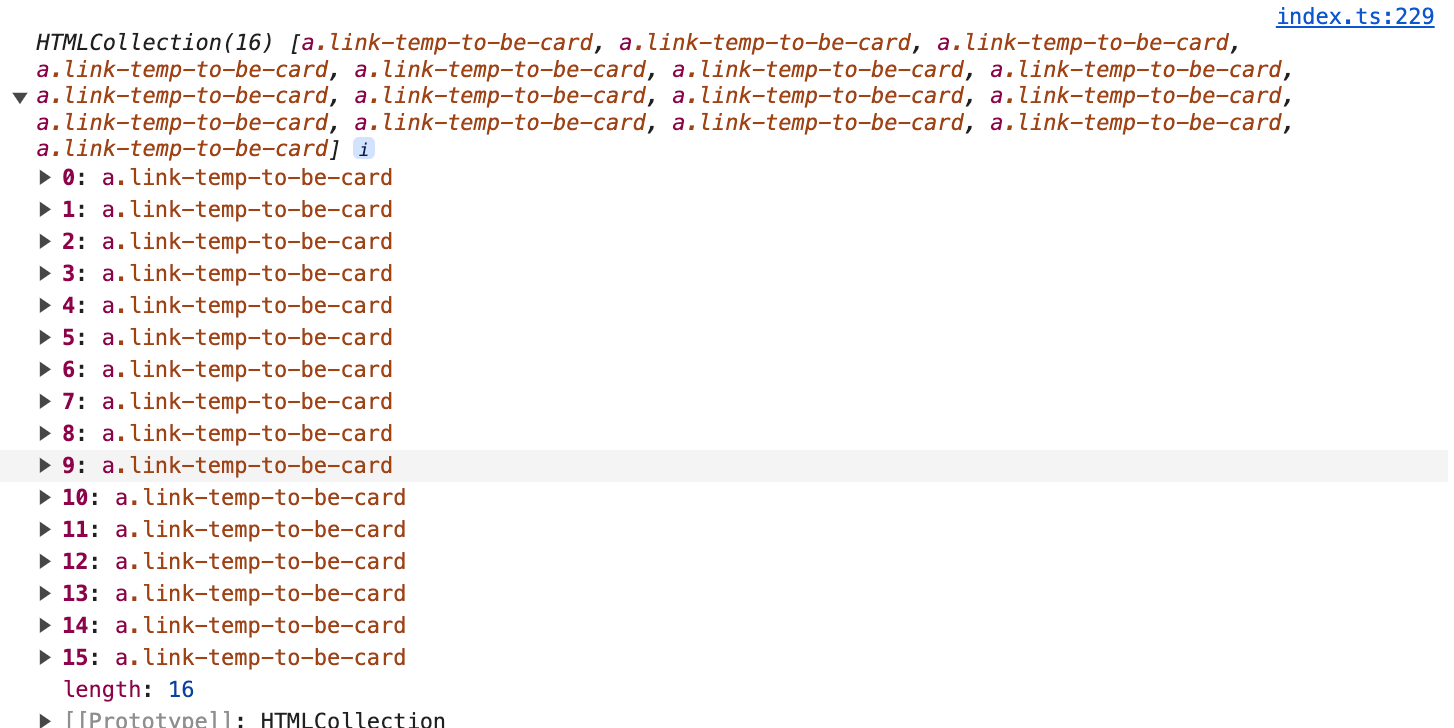
然后遍历替换节点:
1 | const eles = markdownBody.getElementsByClassName(TEMP_LINK_CLASS); |
在上述的代码中,替换节点使用了replaceWith()这个DOM API,而renderSkeletonCard()方法就是生成骨架屏的DOM用于替换。

同时,我们可以请求我们的接口获取网站的配置,将真实的数据渲染到卡片上,这部分的处理逻辑在前文已有谈到,直接贴上最终的效果。

链接懒渲染
由于替换DOM节点时会同时请求接口,当我们打开渲染好的页面时,会瞬时替换所有的链接节点,并瞬时发起请求,而此时链接未必进入到可视区域内,这就会造成服务端的压力和页面的卡顿,因此,增加懒渲染的功能很有必要。
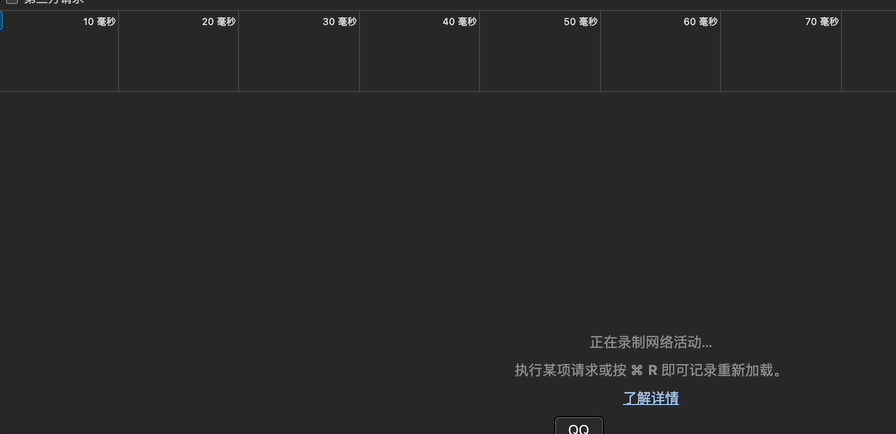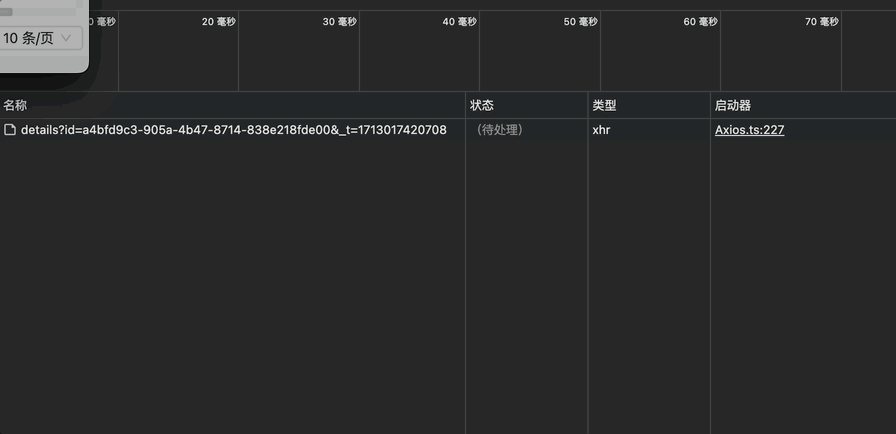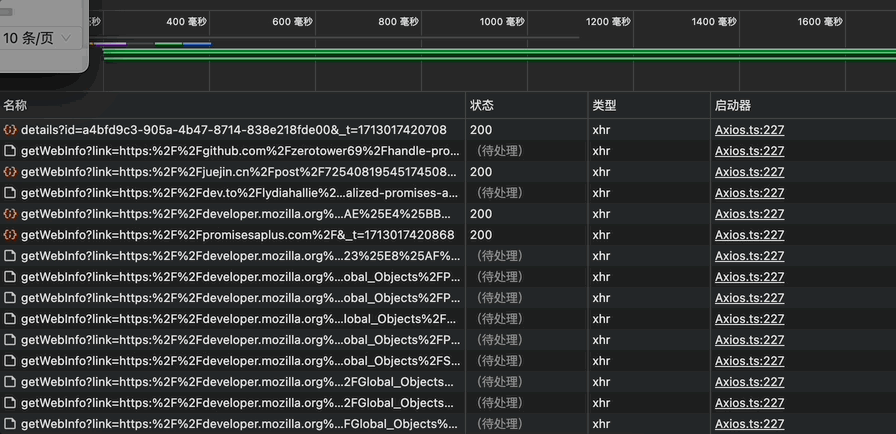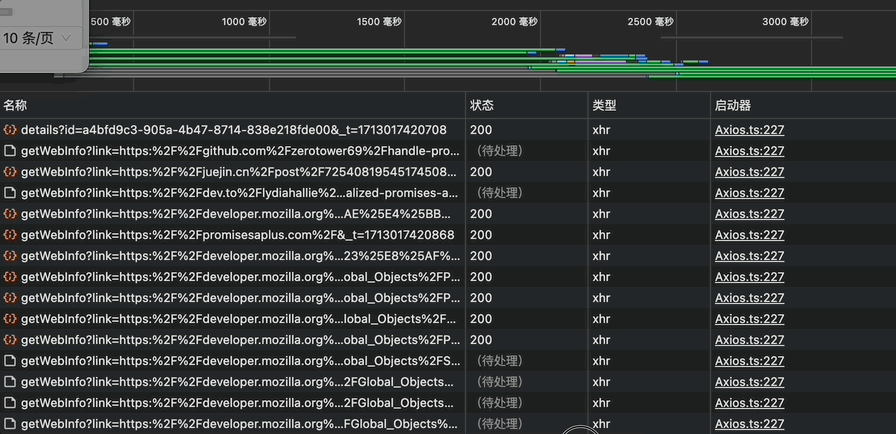
要实现懒加载,我们可以通过IntersectionObserver 这个API实现。MDN上的说明如下:

简单来说,我们可以通过定义一个观察者对象来监听目标元素是否在我们指定或者模块的可见区域内的可见性。
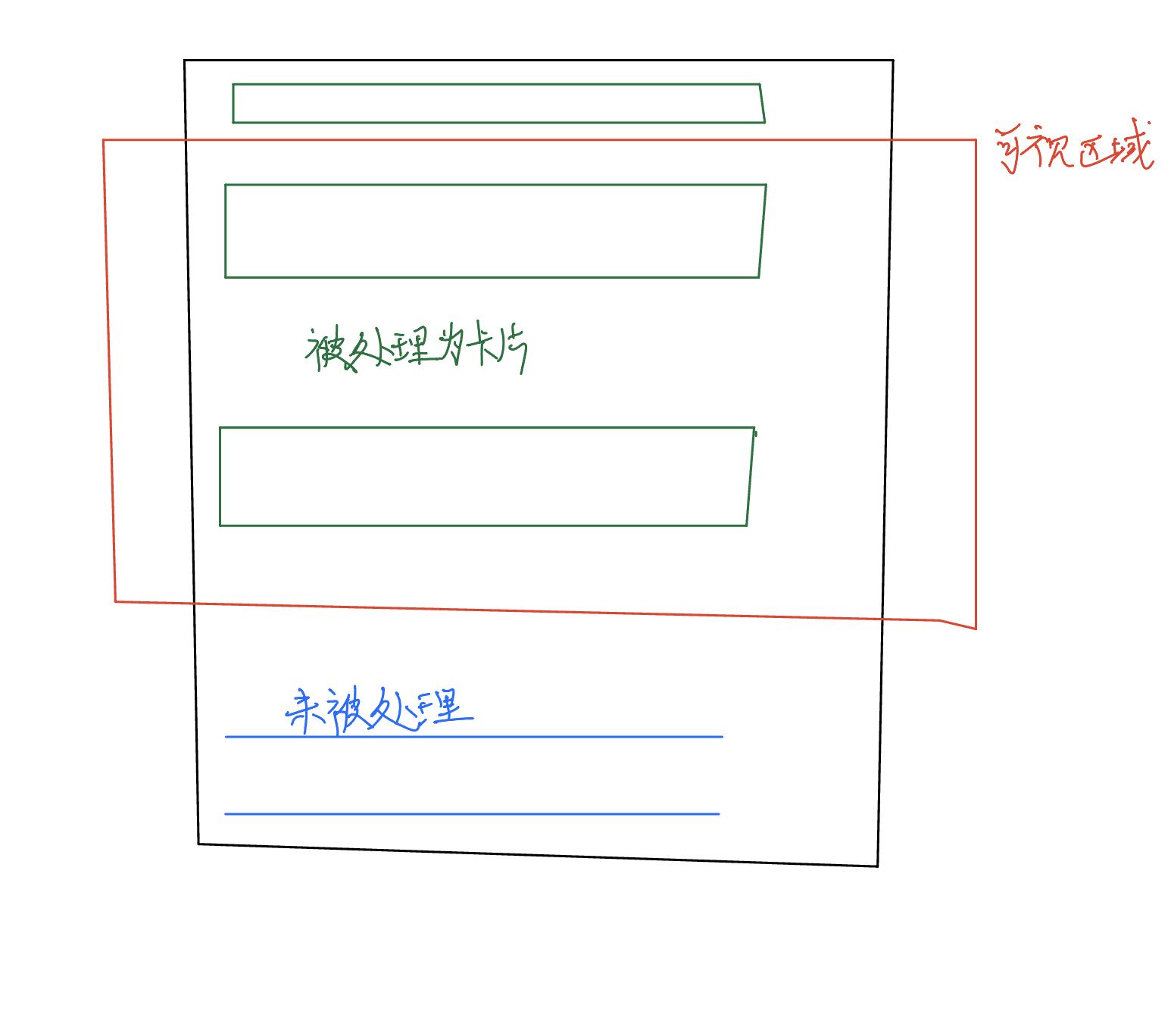
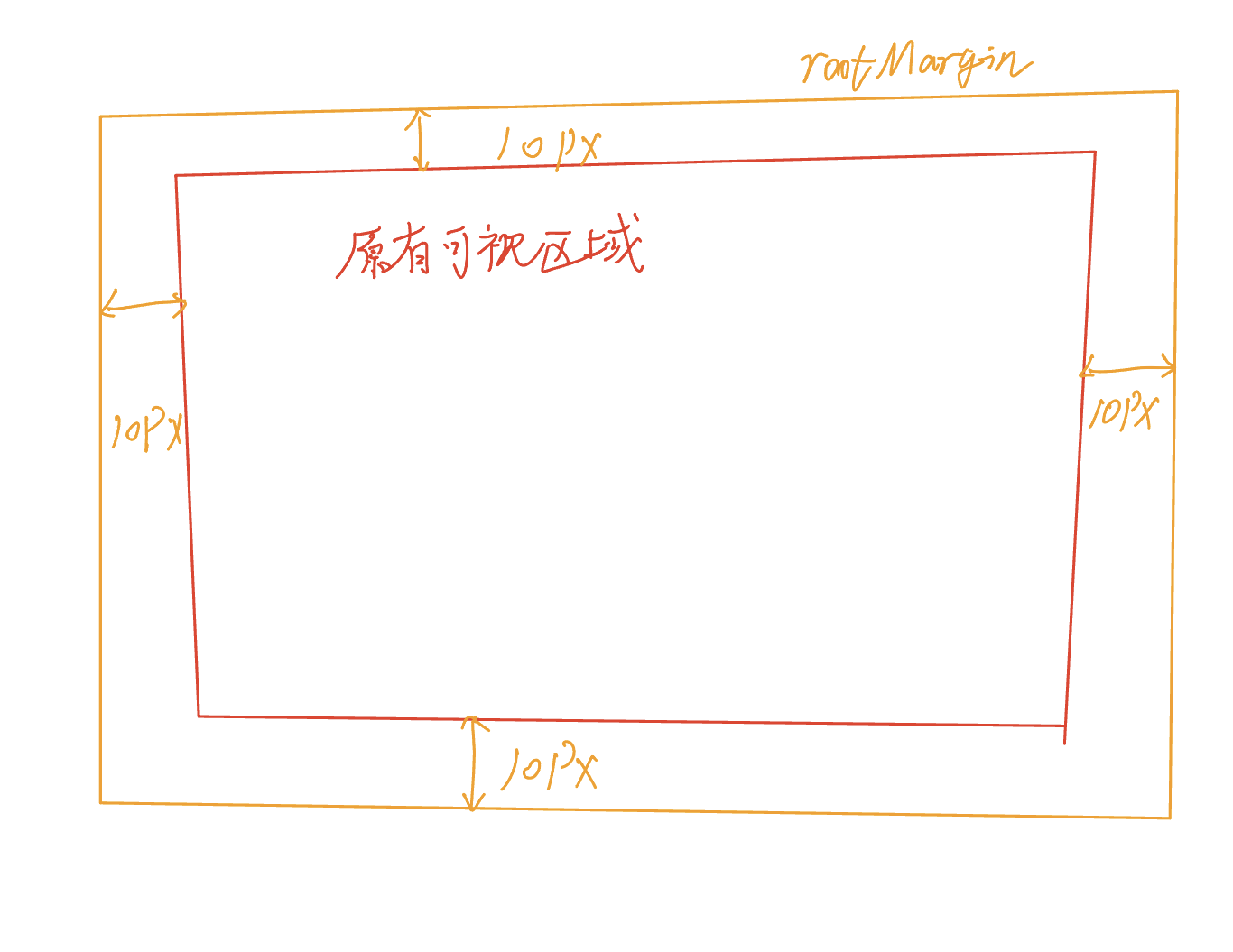
接着,我们可以使用rootMargin属性设置缓冲区,当我们即将滚动到链接时就触发了渲染逻辑,如图所示:
代码示例如下:
1 | intersectionObserver = new IntersectionObserver((entries, observer) => { |
创建一个intersectionObserver观察对象,遍历每个链接元素后,使用observer()方法添加到观察者对象中,只要元素在可视区域的位置发生变化,观察者对象的回调函数将会被触发,回调函数中的entries就是每个被添加到观察者对象的元素的相关信息。对entries遍历,如果isIntersecting属性为true,代表着该元素此时在可视区域内,那我们就将其渲染为骨架屏卡片再渲染为真实的卡片完成小我们的逻辑处理,否则就什么也不干。另外,完成渲染后,应该使用unobserve()方法把该元素从观察者对象中移除。
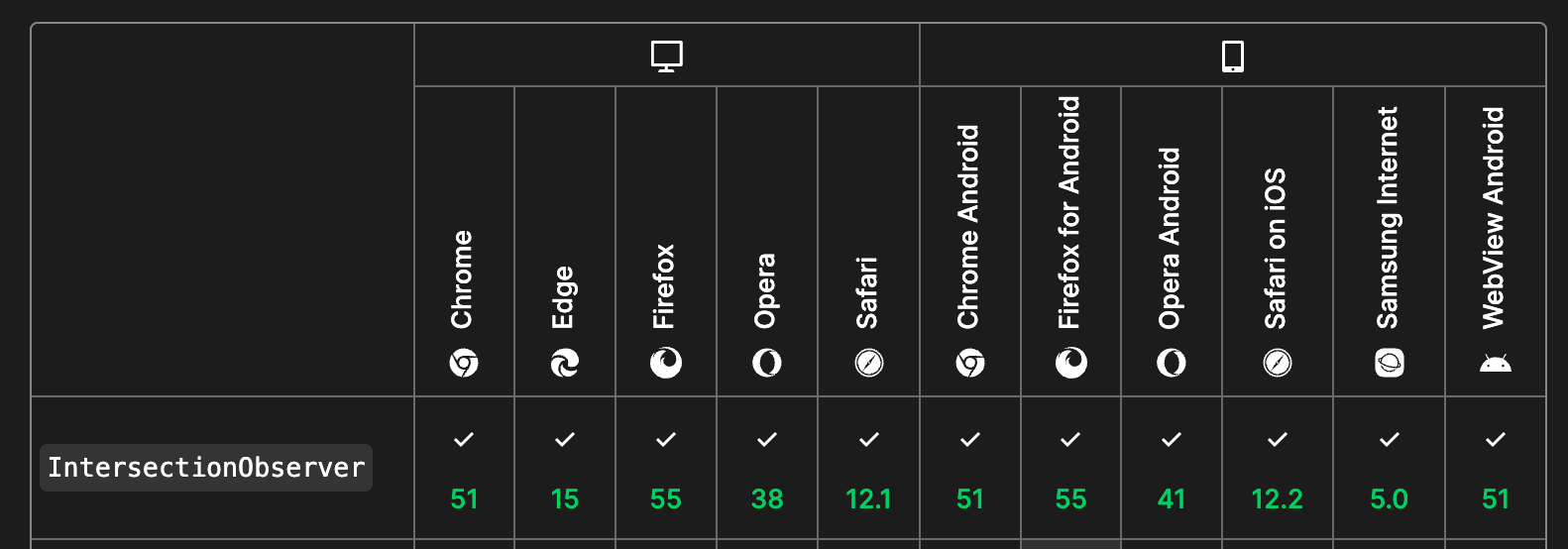
需要注意的是,需要判断浏览器的对IntersectionObserverAPI的兼容性,一旦浏览器不支持,就使用没有懒加载的原有逻辑。不过,现主流浏览器都对其有着较好的兼容性,如图所示。
至此,我们完成了链接的懒渲染。值得一提的是,我们也可以使用该API实现其它需要懒渲染(懒加载)的场景,如图片的懒渲染。
进一步抽取公共配置
到这,我们已经初步了该插件的所有功能,封装前我们还有考虑到一些细节:插件交给用户使用时需要调用的接口应该由外部传入;接口响应超时的时间可以用用户指定,前文说的25s用户可以指定为15s;包括默认的icon链接也可以由用户指定,等等。
1 | export interface ByteMDPluginCardLinkOptions { |
我提供的选项包括:
- 语言选择(国际化)
- 需要排除渲染的链接(支持正则匹配)
- 获取网站信息的请求接口
- 外链打开模式:本标签页跳转或者新标签页打开
- 请求超时设置
- 默认icon图标
- 骨架屏卡片的root元素类名,用于样式覆盖
- 完整渲染后卡片的root元素类名,用于样式覆盖
- intersectionObserver的options配置,可以通过其传入rootMargin和root的值,以设置缓冲区和可视区域根元素。
通过这些配置对插件里的逻辑内容进一步地修改,才是一款真正具有通用性的bytemd插件。
插件打包并发布
插件开发完毕后,我们需要将其打包并发布到npm上。
插件打包
我们可以使用rollup进行打包,我们需要如下插件:
| npm包 | 作用 | 版本 |
|---|---|---|
| rollup | 打包工具 | 4.14.0 |
| @rollup/plugin-commonjs | 代码转为commonjs风格 | 25.0.7 |
| @rollup/plugin-json | 支持导入json文件 | 6.1.0 |
| @rollup/plugin-node-resolve | 支持引入第三方库 | 15.2.3 |
| @rollup/plugin-typescript | 支持处理typescript,并生成类型声明文件。 | 11.1.6 |
| @rollup/plugin-terser | 代码压缩 | 0.4.4 |
rollup 配置文件如下:
1 | import typescript from "@rollup/plugin-typescript" |
需要注意的是,打包时除了dist目录之外,还会生成.rollup.cache目录和tsconfig.tsbuildinfo目录。为了不影响打包结果,每次打包请需要清除它们,我们可以使用rimraf来快速删除我们的目录或者文件:
rimraf dist .rollup.cache tsconfig.tsbuildinfo
最后执行rollup -c rollup.config.mjs命令来生成我们的打包文件。
发布到npm
首先我们需要使用命令npm login登录我们的账号,然后为我们的插件新增一个README.md文件。修改我们的package.json文件,指定我们的包名、版本号、描述信息、仓库地址、作者信息,引用文件路径等,再执行命令npm publish即可完成发布。
如果发布错误,可以使用npm unpublish命令撤销发布,但下一次发布将必须是24小时之后。
总结
本文介绍了如何将markdown中的链接渲染为卡片样式,并进一步封装为bytemd编辑器的插件。
首先我们可以将链接通过节点替换为骨架屏样式,使用puppeteer在后端获取目标网址的信息,并渲染出真正的卡片链接。
接着,使用IntersectionObserverAPI来实现卡片的懒渲染。
最终,进一步抽取公共逻辑,允许用户给定options传入请求接口、约定默认值等;并通过rollup打包后发布到npm服务上。